This Week In Veloren 70

This week, we hear from @xMAC94x about the state of CI in Veloren. @BottledByte has analyzed modding possibilities in Veloren. @Capucho is working on an animation proposal, and @Pfau has an art blog post.
- AngelOnFira, TWiV Editor
Contributor Work
Thanks to this week's contributors, @Imbris, @Shandley, @zesterer, @Pfau, @scottc, @Slipped, @xMAC94x, @Songtronix, @qrazhan, and @CapsizeGlimmer!
This week, @lobster added more information to the character window. @xMAC94x has been working on lots of CI improvements. He also has been continuing work on networking, and some changes are currently in review. @badbbad has created a new ambient night audio track. @Capucho is working on an animation proposal, you can check it out here. Social window work by @lobster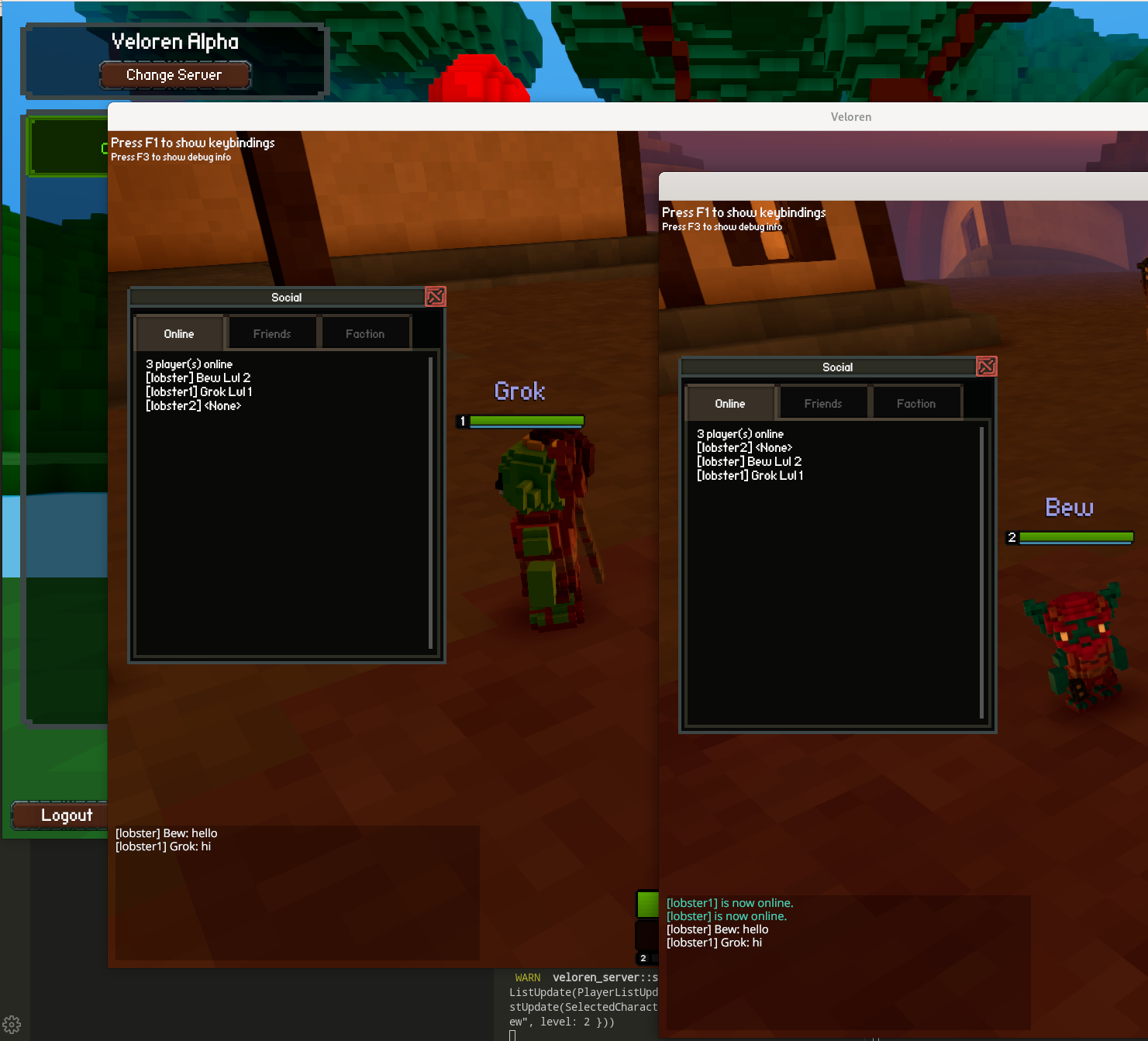
@Shandley merged inventory and layout persistence. @Pfau has been working a lot on the UI, and has a new art blog post, which you can check out here. @Snowram has been working on adding a snake and worked with @Slipped to improve small quadruped animation. I'm Home by @badbbad
Mod Analysis by @BottledByte
I have been trying to add a WASM interpreter to the Veloren's codebase. Also, because I was curious, I did more research on both Wasmtime and wasmer. As per @Capucho's proposal, I have tried Wasmtime as the first option for Veloren's WASM integration. After about 3 hours, I gave up, as my attempts to integrate wasmtime failed. This was because most of Wasmtime's structures are not thread-safe.
I was unable to figure out a nice and easy way to implement design for its use. It appears to me that Wasmtime is not designed to be used in multi-threaded environments without additional work on user's side. Maybe they will make it thread-safe one day, but that is the future. As an example of this, here is a quote from their documentation:
It is intended that Memory is safe to share between threads. At this time this is not implemented in Wasmtime, however. This is planned to be implemented though!
So, I tried to integrate wasmer instead, and it only took 10 minutes! This was because wasmer's internals are thread-safe by default. So I was interested in pros and cons of Wasmtime and wasmer and did some primitive benchmarks. Here are rough results using relative measurement:
> Compilation
wasmer was ~120% slower than wasmtime
> Instantiation
wasmer was ~120% slower than wasmtime
> Execution
wasmer was ~25% slower than wasmtime
Well, that could not be more obvious, wasmer is just slower than Wasmtime. However, both compiling and instantiating can be alleviated somewhat. These benchmarks are not of real-life cases, I admit. However, even in case of a simple for loop, wasmer was slower. Micro props for details in houses by @SausageRolls
Also, the background and goals behind Wasmtime and wasmer are different. Wasmtime's creators, Bytecode Alliance, is a syndicated effort of industry giants to "push WASM forward". On the other hand, Wasmer Inc. tries to bring WASM into production and "real-life" applications. In my opinion, Wasmtime will have high ground in features, while wasmer will have nicer APIs. Despite its current synchronization quirks, Wasmtime seems like a good bet for the future. wasmer is there, too, and it makes things a lot easier, but sacrifices speed and features.
Or the Veloren project could wait some more time until Wasmtime gets polished. In the meantime, some data-driven modding methods could be used. This means exposing more functionality through config files. It is simpler, both for modders and for API implementors, and it still reduces compile times a lot.
Improving CI by @xMAC94x
@xMAC94x spent the week improving the current CI situation. Over the past year Veloren has grown a lot. However, we didn't focus enough on keeping the project clean. The result is that CI is a bit dusty right now.
What is CI?
CI stands for Continuous Integration. It means that our code is integrated through tests every time we want to merge code. Most of our testing is done automatically, giving the devs more time to focus on creating new stuff while consistency and stability guarantees are provided by the CI framework.
It's the responsibility of the contributors to write these tests. Usually, you try to define many tests, including benchmarks, performance tests, functionality tests, and integration tests. When a contributor wants to change something, all tests written by all contributors are run in the CI. If a test fails, the developer will be notified and can fix their bug. This must be done before the code can be merged and go live. New hourglass by @Pfau
What's wrong with our CI?
We are missing tests, we only have 1.17% of our source code covered. Is that bad? Yes and No. While 1% itself doesn't mean that we have bugs in Veloren, it means a bug could hide happily in 99% of our source code without us noticing. This number should go up. Having more than 80% is recommended and projects tend to profit in the long term from good test coverage. (Note: A high test coverage itself is no guarantee for a good project).
Our CI is slow. CI is required to run for developers to merge. If a contributor changes something they have to wait for feedback from CI, which can take up to 2 hours currently. Our CI is error-prone as well, but isn't consistent with the problems. Imagine your CI is like a traffic light, it either sends you a red or a green signal. You want to be able to trust that signal. It should be reliable and not fail. If it shows red to all 4 directions, people are annoyed why they have to wait. But if it falsely shows green to the wrong people this could lead to a catastrophe. Luckily in our case, the later one doesn't happen often. Snake by @Snowram
How to fix CI?
Okay, we identified some issues with CI, how will the Veloren team improve it?
Improving code coverage. this has to be aligned with core devs first, but the only way to get it to work is to encourage people to always add tests. An extreme case would be to forbid changes without tests, however, we would rather not enforce that.
More effectively using caches. Our codebase is quite large currently, and changes are small. When any change comes in, our CI computers often restart from scratch. We can configure CI to cache the results in order to speed up the tests. However this hasn't worked out until now. (more below)
Fix broken runners and include
verify post-merge result(more below)

What was done this week
I spend a lot of time today working on improving caching. We are using GitLab CI as it provides the awesome functionality to host own runner and configure them as needed. A few months ago @Acrimon switched our toolchain to use docker and @Songtronix just recently enabled the new powerful GitLab rules to modify behavior our CI tests.
As compiling Veloren is slow, CI is also slow. We tried to use all kind of caches, including the GitLab internal ones. This doesn't work though, because they zip everything, as we have up to 15 GB of generated files. Zipping them takes more time than just having no caches at all. For now we are going with prebuilt caches. Once a week we prebuild the cache in a nightly job, this will then be reused every time. Such a prebuild can really be super efficient end eliminate all dependency compilation, only keeping the linking times. However, this simply doesn't work. We couldn't figure out why, but some cache where just ignored.
What it took was some testing. As I spend some time with cargo I got to know that it's far from perfect. cargo had separate caches for debug and release build no matter what. However, we are generating much more builds than just debug and release complicating this even further. We are running the following tasks in CI check, build, test, benchmark, clippy, tarpaulin, audit, windows release, linux release, and macos release. All these try to use the same cache. I found out that this just didn't work.
One would expect that if we already filled the cache with the check job that the next build will be sped up, unfortunately this is not true. It will just ignore everything and reinvent the wheel. At least this is not destructive. When we ran test once, then ran tarpaulin, it destroyed all cached data till now, so a second test would have to start all over again. The same goes for the multiple release builds, somehow windows release was resetting all progress on a linux release.
So how did we fix it? The solution might sound too stupid to function, but it does work. We just use different directories to store the results. We make sure that tarpaulin, windows release, linux release, and macos release all get a separate directory to store their builds. All the other jobs are fine to share the same directory, their caches work as intended. With this, compile times goes down to under 30 minutes for all those tests. Besides saving some electricity, this really saves the sanity of our contributors 😊 (and my sanity ofc, it was annoying me so much that I had to do something)
What needs to be done
We disabled some jobs on master this week. This removes the ability to check if our merged result is still functioning correct. The usual Git Merge workflow is the following:
- A contributor creates a new branch off of master
- The contributor adds some new changes to their branch
- In the meantime, other people work on master
- The contributor merged their changes back to master
We should be running tests for both 3. and 4. before it is merged into master. However, we only run tests on the contributor's branch, without a simulated merge. Therefore, errors can occur during the merge. If this would happen, we would have a bug in master. And master is the version distributed to the server and via Airshipper. So this should never happen. A feature called verify post-merge result would help here. It would kick in on step 3 and simulate step 4 before executing it. If an error would appear now, it could be addressed before it goes to the players.
Next Steps
To achieve better test coverage we probably need to discuss with developers what's the best approach to take. It's not essential to force there to be more tests everywhere, but we need to take a more proactive strategy for testing.
I will be continuing my work on networking. Additionally, I will try to reduce Veloren's compile time by reducing its dependencies, I am happy to present them in the next post 😃 Chunky boi chillen, see you next week!
