This Week In Veloren 75

Welcome to the longest Veloren blog post so far! This week we hear from @xMAC94x about the network switchover. @imbris discusses an interesting bug. @zesterer overhauled pathfinding and wrote about how it's better. @Sharp shares some insights about how GUIDs might not always be the best. Timo went hiking and biking.
- AngelOnFira, TWiV Editor
Contributor Work
Thanks to this week's contributors, @zesterer, @xMAC94x, @lobster, @Songtronix, @imbris, @ProTheory8, @Slipped, @Snowram, @Qutrin, @AngelOnFira, @XVar, @Sam, @Pfau, @KevinGlasson, @Nancok, @theduke, @Patro, @Redo11,and @Swedneck!
There is a new Rust gamedev newsletter to check out! @Pfau also has a new edition of his weekly Veloren art blog. The team met this last weekend for a 0.6 halfway meeting. Testing knockback values on a new hammer attack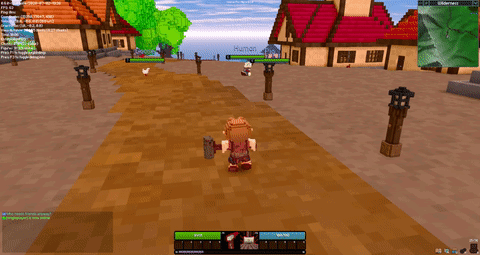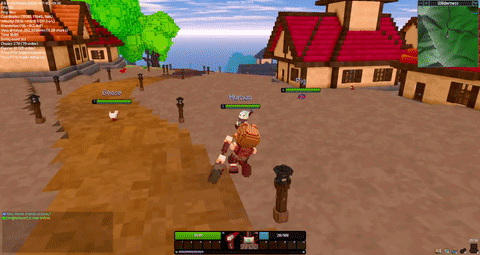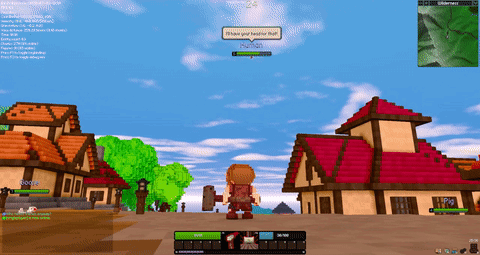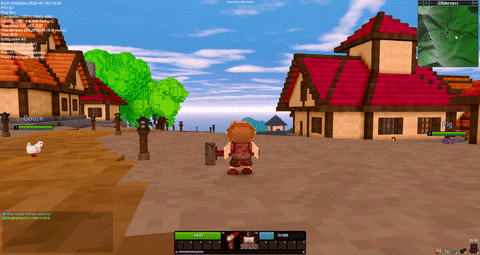
@Songtronix fixed an error with preventing the book from working with Zola 0.4.1. The art team worked on improving spell and attack icons. They decided on a colour code system for icon backgrounds so that the player instantly knows what category it is in. For example, red means physical, while green means healing.
Qutrin implemented a loot table system that allows choosing drop rates for items. @lobster was working on one-handed weapon fixes, and started working on particle effects. @WelshPixie had to resort to proofreading lore docs since there is currently a technical block on adding lots of sprites like she wanted. @Snowram helped @Slipped to finish the quadruped rework. Skunk by @Gemu
@XVar the foundational backend implementation of skills and skill groups, and is now waiting for game design to come in with some preliminary skills to get into the game. @Gemu has been making progress on the small-quad reworks, such as the skunk. @Felixader is working on a few things. First is the design description and history behind the ideals of how the different cultures construct their cities. Second is cultural design philosophies for items. Finally, he is working on a structure for writers can format ideas for quests, lore items, and other writing items. This will have to be discussed with other groups to make sure it fits nicely.
@Sam finished a new hammer attach which has been merged. They are now working on a new spinning axe attack. @JackRubino has completed an update to the Italian translation. @Sharp is still hard at work their monumental LoD and shadows branch, otherwise known as sharp/small-fixes. There is hope that this branch will be merged soon!
Networking Milestone by @xMAC94x
In the blog we've covered a lot about networking recently. Last Friday we reached a networking milestone. The alternative networking backend got implemented into Veloren and will be active from now on. While no additional features are activated yet, everything is prepared to have it enabled seamlessly in the future. Rolling mountains by @Treeco
Network Switchover
The switch itself was quite a success considering it was switching the whole networking layer under the hood. There were a few problems, however:
- Server had a problem of too much logging which was fixed within an hour of discovery
- Clients would panic if the server disconnected them, which was also fixed within an hour
- When a clients disconnects from a server they had to wait 20 seconds for the timeout before reconnecting
None of those errors caused game-breaking behavior. Unfortunately, we had a further difficulty as our network frontend was sending way to much data (10 Mbit/s per player even on idle). This required lz4 compression to be reenabled to serve more than 4 players at a time on the official server. New icon for the axe skill
Beside that, we were doing a lot of testing and found multiple other unrelated bugs in Veloren:
- Some messages from the server were getting dropped for a while now. Additional logging is now provided so this can be prevented in the future.
- Entities are no longer in sync when you leave spawn and come back
- Our netcode sends way too many inventory syncs, @imbris pushed a fix on Monday
- Crash due to missing green pants item
- Render distance not adjusted correctly
Next Steps for Networking
The next steps for Veloren networking are quite clear:
- Improve stability
- Work on the great list of stuff to improve from @Songtronix, @zesterer, and @imbris
- Enable the multi-stream channel which will allow faster entity sync transfers even while there is a heavy bandwidth load
- Better network statistics in Grafana, which will be beneficial for development and release parties
- Invest in testing and scaling with multiple players (automated tools for high player-load tests)
- Enable the UDP backend, which will decrease latency significantly
- Network feedback to its ECS systems e.g when bandwidth is slow in order to reduce a player's tick count. This might enable higher tick servers)
Those steps will be tackled within the next weeks and months, so stay curious 🙂
The Case of the Disappearing Entities by @imbris
A bug was found that caused entities to randomly vanish. At first, it was thought to be caused by some NaN in the code or a malfunction in the region system used to select what entities to sync to each client. This could be reproduced with the following:
- Open the game
- Go from far enough from spawn town that you can't see it
- Go back to spawn town
- Try rolling, shooting bow, or spawning entities
The culprit can be seen in the image below. On login, the client sends its requested view distance to the server. The server makes sure that it's constrained to a maximum allowed view distance. The code handles this by sending the client an updated view distance if it was over the maximum. If you look carefully at the map the two parameters are disordered leading to the client always receiving a message telling it to use the max view distance.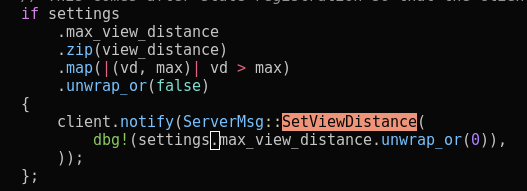
However, if the client initially requested a smaller value the server will still think that is the value being used. Additionally, the view distance in voxygen is never updated because the client uses an event returned from tick to inform voxygen of this change. At the time of the bug, voxygen ignored all events from the client while on this screen because they were previously not relevant.
So we end up with a scenario where the server and voxygen both have the selected view distance, say 10, while the client thinks the view distance is the max configured on the server, say 30. Thus, the terrain renders as you would expect but the client doesn't unload chunks farther out since they are still within the view distance that it knows.
However, these chunks are unloaded on the server since it sees them as being outside the client's view distance. Then, once the player goes back to the spawn town they will see the terrain chunks that the client held on to but the client won't request the server to reload them. Additionally, since the area is not actually loaded on the server any non-player entities will be deleted.
Pathfinding with @zesterer
I made a bunch of changes to pathfinding this week. The biggest improvements come from three places: heuristic modifications, velocity alignment, and cubic spline motion planning. Previously, pathfinding worked something like this: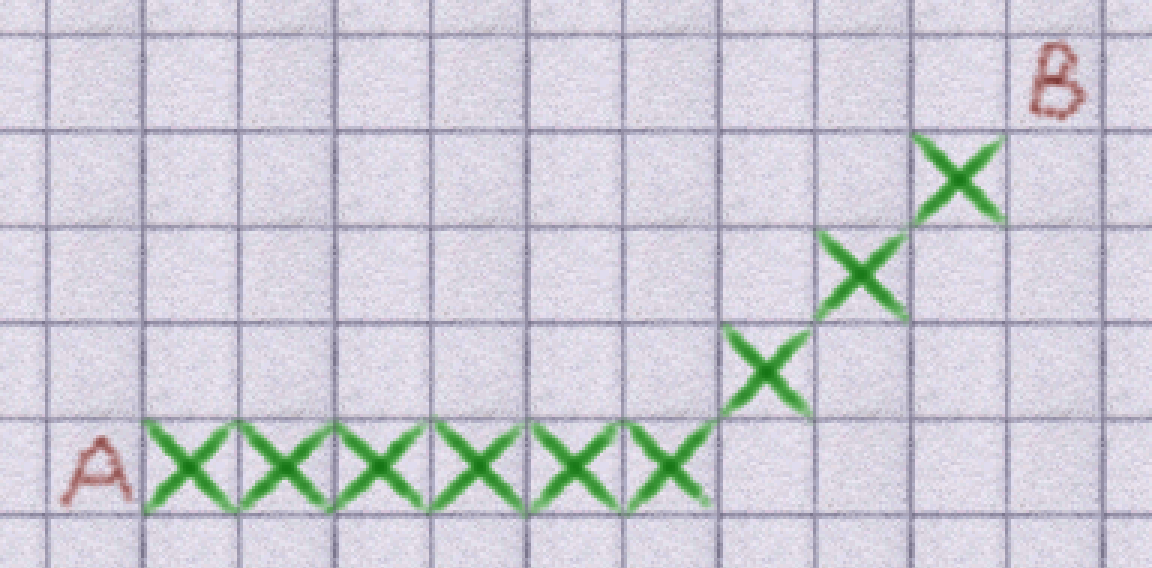
Getting from A to B used the A* algorithm with a basic distance heuristic. This resulted in paths that felt a bit odd. Enemies wouldn't run towards you in straight lines and pets would make bizarre robotic movements in order to catch up with you. This happens because the pathfinding only considers the most 'locally' efficient path to the goal: and since it can only consider the 8 neighbouring blocks, the best it can do is to choose the block that moves closest to the target from the source block.
To solve this problem I modified the pathfinding heuristic to make A* prefer to use paths that are closer to a straight line to the target. This means that they now prefer paths that are shorter from the perspective of an agent that can move freely rather than one that can only do King moves in chess. This adjustment to the heuristic is actually very small: in most decisions it has almost no impact, but it's enough to act as a tie-breaker between two options that appear to both be optimal from the local perspective. The result is that it now produces paths that look like this: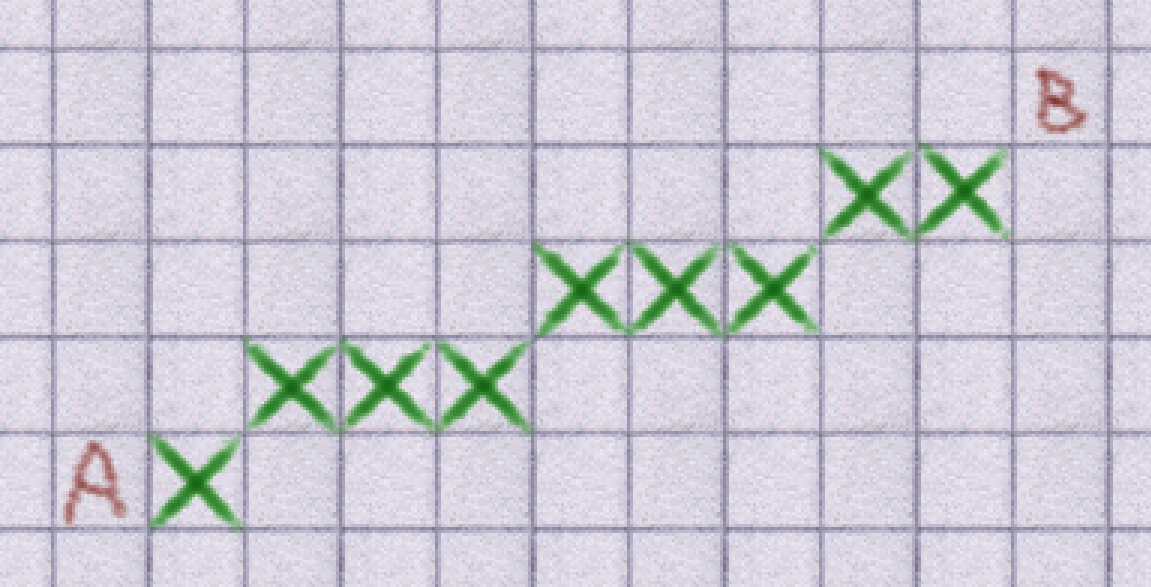
This feels a lot more natural: enemies run towards you in relatively straight lines, as do pets. However, there were still problems. In fact, this method introduces even more problems. Agents follow path nodes one at a time, aiming for the centre of each block. This resulted in lots of small turns appearing in the paths agents took. Where the old system created paths with lots of straight lines like this: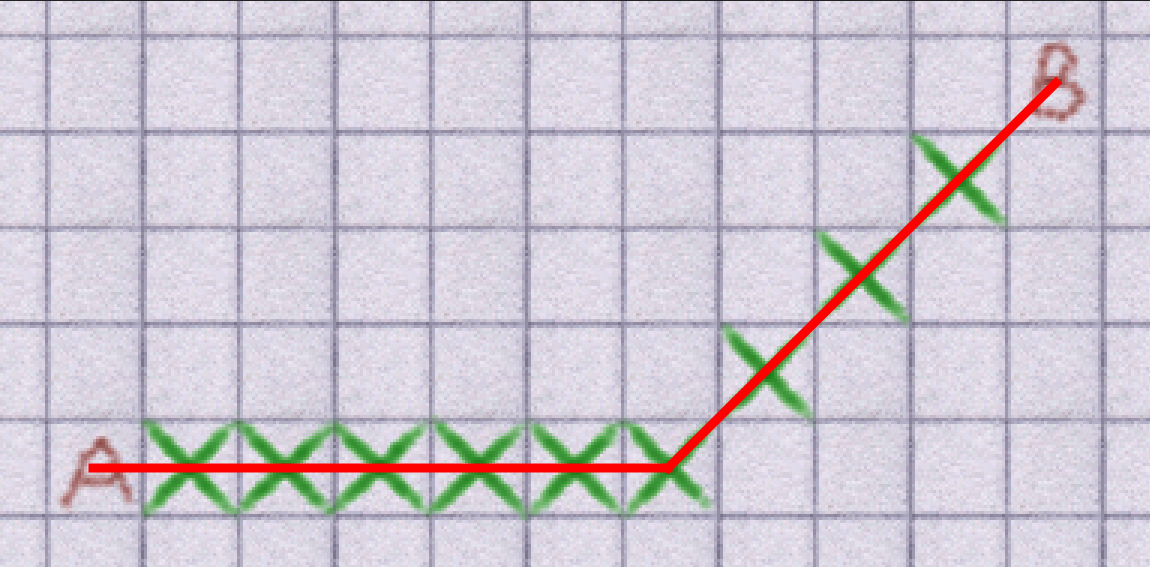
The new system created paths with lots of small turns like this: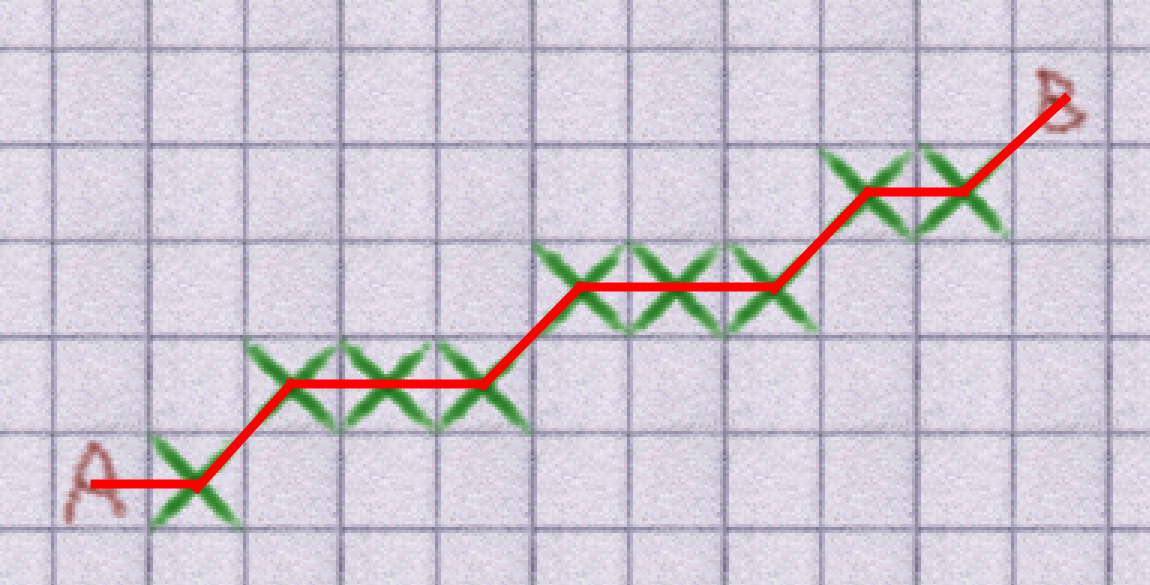
This results in a lot of jerky movement: agents zig-zagging as their run, and a lot of ugly rapid rotation. To alleviate this problem I came up with another solution. I realised that the primary problem was that agents were aiming for the centre of each block and that the resulting motion would look much smoother if the agent instead aimed for the 'most convenient' position to hit within that block.
'Most convenient' can be a little hard to pin down, but a very good approximation of it can be found by looking at the agent's current velocity vector. The most convenient position within a block will be that which requires the least deviation from the current velocity to reach. This might initially seem like a daunting problem: agents move with smooth movement using floating-point numbers, so the number of points in the block to consider would be, in practical terms, infinite.
However, this actually boils down to a simple linear optimisation problem. It turns out that an optimal solution will always appear on the edge of the block. To solve this, we can instead just find the intersection between the current velocity vector and the line that represents each edge of the block. The result is that we can achieve smooth motion even if the pathfinding itself remains grid-aligned. As a result, the path the agent actually takes looks like this: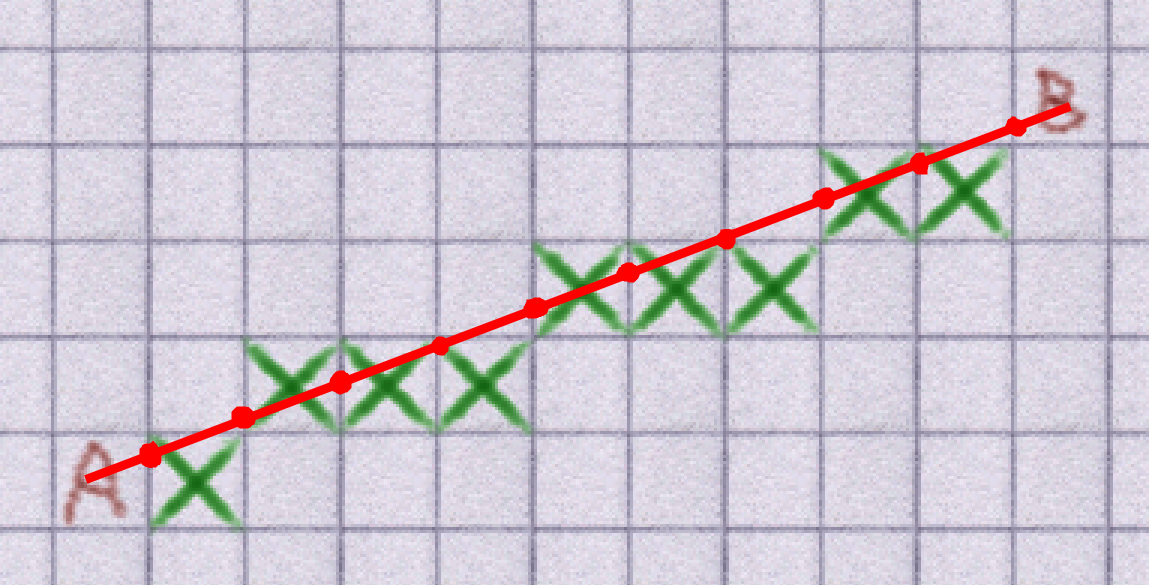
There's a secondary advantage that comes with this technique too. As it turns out, considering diagonal blocks makes pathfinding much more expensive. This is because validating that a diagonal block is accessible first requires that determining that at least one of the two blocks adjacent to the source and target blocks is accessible as well. This adds a lot of overhead to pathfinding.
The original reason for adding diagonal pathfinding was to create smoother paths: but this new technique blows diagonal pathfinding out of the water for that! As a result, we can actually remove the diagonal pathfinding and get away with adjacent cardinal pathfinding instead. The result of this is a path that looks like this: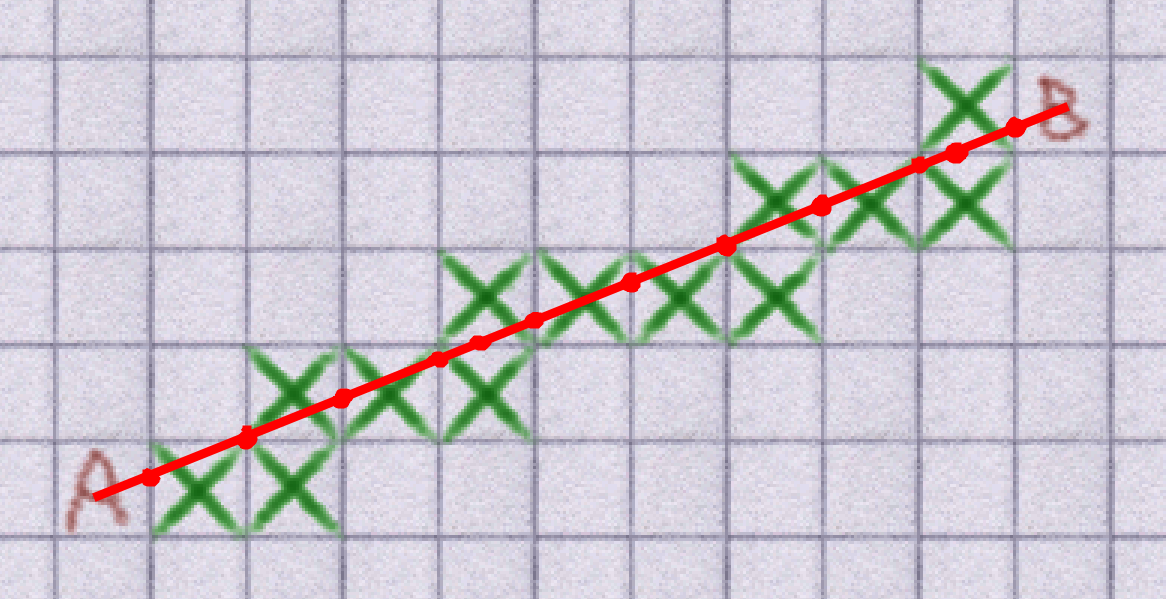
Although this path has more nodes than the previous one, it's also much faster to find (it might also be possible to do post-processing cleanup on it afterwards but to be honest this isn't really needed due to the aforementioned velocity-alignment pass). The result of this is that pathfinding has become a lot faster and can do more useful work per frame. This allowed me to up the per-frame pathfinding iteration budget significantly meaning that agents discover complex paths in far fewer frames than they previously could.
Lastly, I noticed some problems with the new animals. Many new animals, such as wolves, got introduced recently. I wanted to make them (and other creatures) feel a bit more natural so I added per-species movement speeds. The problem is that wolves now run at almost twice the speed that they used to: and the existing pathfinding code simply couldn't cope. It tended to overshoot path nodes, understeer on corners (leading to wolves falling off a lot of things), and it turned them into terrible hill climbers since they kept moving too fast down slopes, causing them to fall and hurt themselves.
The previous approach to pathfinding involved moving in a dead-straight line towards the next path node. This worked fine for slower animals but, as mentioned, breaks down completely here. The agents would attempt to follow the following path: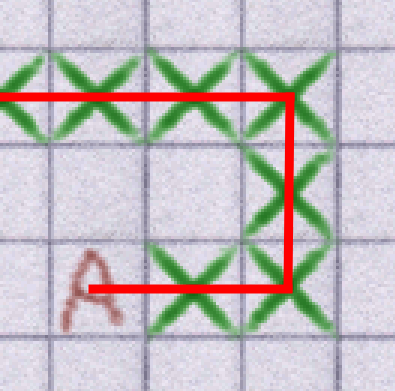
But in practice, this didn't take into account the reality of their own momentum, which resulted in them taking something closer to this path: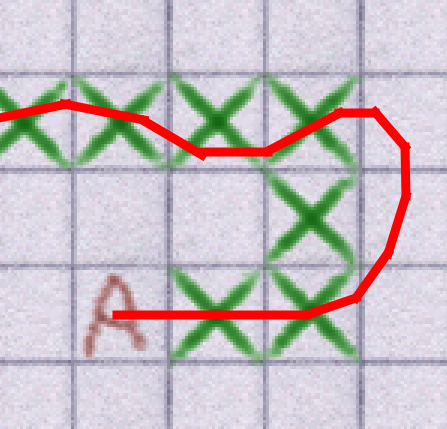
I reality, this problem was even worse: wolves would willingly hurl themselves off narrow paths to their deaths with surprising vigor. To counter this problem, I made them decide on a movement direction by constructing a cubic Bézier spline (i.e: a curve) that took into account the following things:
- The agent's current position
- The agent's current velocity
- The positions of the next two nodes
The result of this is a curve that goes from the agent's position to the n + 1th node in the path, but curves to take into account the current velocity (to keep movement smooth in the general case) and the nth node (to avoid erroneously cutting corners).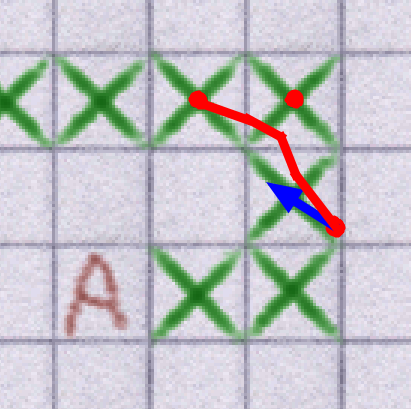
This seems to work quite well for keeping movement smooth but unfortunately, it doesn't help slow agents down on corners to avoid their untimely death. To solve that problem, I added one last feature: agents now regulate their movement speed by taking the cubic path tangent a little into the future and performing a dot product against their current movement direction. This slows the agent down if their current movement direction deviates significantly from the direction of the path that they'll soon be needing to take. This, for the most part, solves the problem.
It's not a perfect solution: it doesn't (and shouldn't - agents shouldn't always have access to this information) take into account the physical properties of the world around them - friction with the ground, air resistance, their own movement capabilities, etc. - but it's good enough that agents move in a manner that feels relatively reliable and realistic.
I've also made a tonne of extra tweaks to pathfinding, too small to mention here, but these 3 changes were the big ones that had the most significant impact. There's still more that can be done and I plan to improve pathfinding further in subsequent feature branches. For now though, this is a significant improvement.
GUID Insights by @Sharp
GUIDs, or UUIDs, are a type of ID that uses 128-bits numbers to identify information. GUID stands for "Globally Unique Identifier", while UUID stands for "Universally Unique Identifier". They take the form
123e4567-e89b-12d3-a456-426614174000. @Sharp and I had a discussion about their potential downsides, and the misconception that sequential primary IDs are outdated. - @AngelOnFira
First and foremost, this is not arguing that GUIDs should never be used. Rather, I'm more arguing that you should think carefully about the kind of key you use and choose the right one for the job. So basically, the primary issue with GUIDs is that they're very large and very spread out in keyspace. These are of course exactly the properties you want from GUIDs, so this is a fundamental tension.
Any methods that rely on data being "almost sorted" or the ability to quickly find a page on the hard drive containing a GUID will not work. For pretty much any index type other than a hash index, you are going to have pathological behavior for any update operation you care to think of as a result.
Secondly, due to the space increase, foreign keys and indices are larger (often 4x or more larger). This makes it much harder to normalize your database and get good performance. I've found many instances where people told me they had to denormalize their database for performance, but it turned out to just be about GUID overuse. New axe spin attack by @Sam
This also applies to other operations like aggregation. Even if they don't need to touch the GUID column, they're slower because they need to read more information from disk. Note: this doesn't apply to OLAP databases with column storage, but these are usually not what's used for most applications during regular operations.
So you're paying a very large penalty on essentially every operation on your database other than nested hash lookups for the privilege of using GUIDs. The nested hash lookups, while the only available query plan in a lot of key value stores, are often suboptimal for industry-strength relational databases.
There are other performance concerns as well. Often, host languages have even worse support for GUIDs than the database; in many dynamic languages the GUIDs end up being read as strings. This introduces substantial serialization, network, and parsing overhead over integers (and it's measurable). Work on @Sharp's shadows
One thing that's often argued in favor of GUIDs is that it's virtually impossible that they will ever overlap. However, most databases will want you to create a primary key anyway which guarantees uniqueness, so this advantage doesn't really benefit you except in a very distributed context. Moreover, the advantage is very easy to get with mostly-sequential IDs too; you just include a "core" or "machine" identifier in your generated ID.
This still produces compact IDs in the same local domain, but without requiring synchronization. This can also be extended to secure contexts; IDs are sequential within an organization or other security domain. Since your security should never be based on someone knowing a particular ID value in the first place, this also encourages much better secure design (in my experience). People who rely on GUIDs have a tendency to assume that, since it's so unlikely that they could be guessed, they themselves function as a security barrier. They forget about all the side channels through which they can be passed. Starry night by @Treeco
GUIDs excel where loose synchronization is needed and there isn't a centralized registry, or where the GUID can do double duty (for example as a hash of its contents). Git is a database that would make absolutely no sense with sequential IDs. GUIDs of some sort (or at least, much larger keys) can also be really useful in a database with a different mechanism for achieving performance. For example, distributed key-value stores. However, they will still not achieve nearly the kind of performance that a small-key-optimized one can no matter how much you scale out, but they can often store far more data.
However, even then, it's useful to be able to specify ranges so that you can redirect key lookups to the correct partition without having to do a full hash lookup. This kind of value-based partitioning scheme works best when values with high locality are clustered. So just doing a global GUID is usually not the best approach even there.
Anyway yeah, for a tiny database or a system that doesn't get much traffic, I realize this is mostly academic. I just have seen way too many people get bitten by GUID performance and not realize it. I think a lot of people assume that sequential IDs are outdated and GUIDs are just categorically better now. At least that's the impression I've gotten. It's mostly that idea I want to fight back against. Ocean of Clouds by @SoullessTeacloth. See you next week!
