This Week In Veloren 125

This week, we get an in-depth view into what was required for the wgpu integration. We see some changes to econsim, performance, and caves.
- AngelOnFira, TWiV Editor
Contributor Work
Thanks to this week's contributors, @YuriMomo, @zesterer, @Slipped, @xMAC94x, @SWilliamsGames, @Christof, @aweinstock, @Sam, @juliancoffee, @Yusdacra, @imbris, @DaforLynx, @donovanlank, @AngelOnFira, @Capucho, @Snowram, @Zakru, and @Kisa!
@Sam worked on a harvester rework. It'll have 4 unique attacks and all-new AI. To see it, go visit your local T0 dungeon (after it merges).
Lava and performance by @aweinstock
This week, I added Lava to caves, which glows, and which sets you on fire when you enter it.
I also improved the performance of entity-terrain collisions (one of the main parts of physics) by an average of 20 microseconds per frame by adding a check for a more precise bounding box before looking up voxels in the terrain.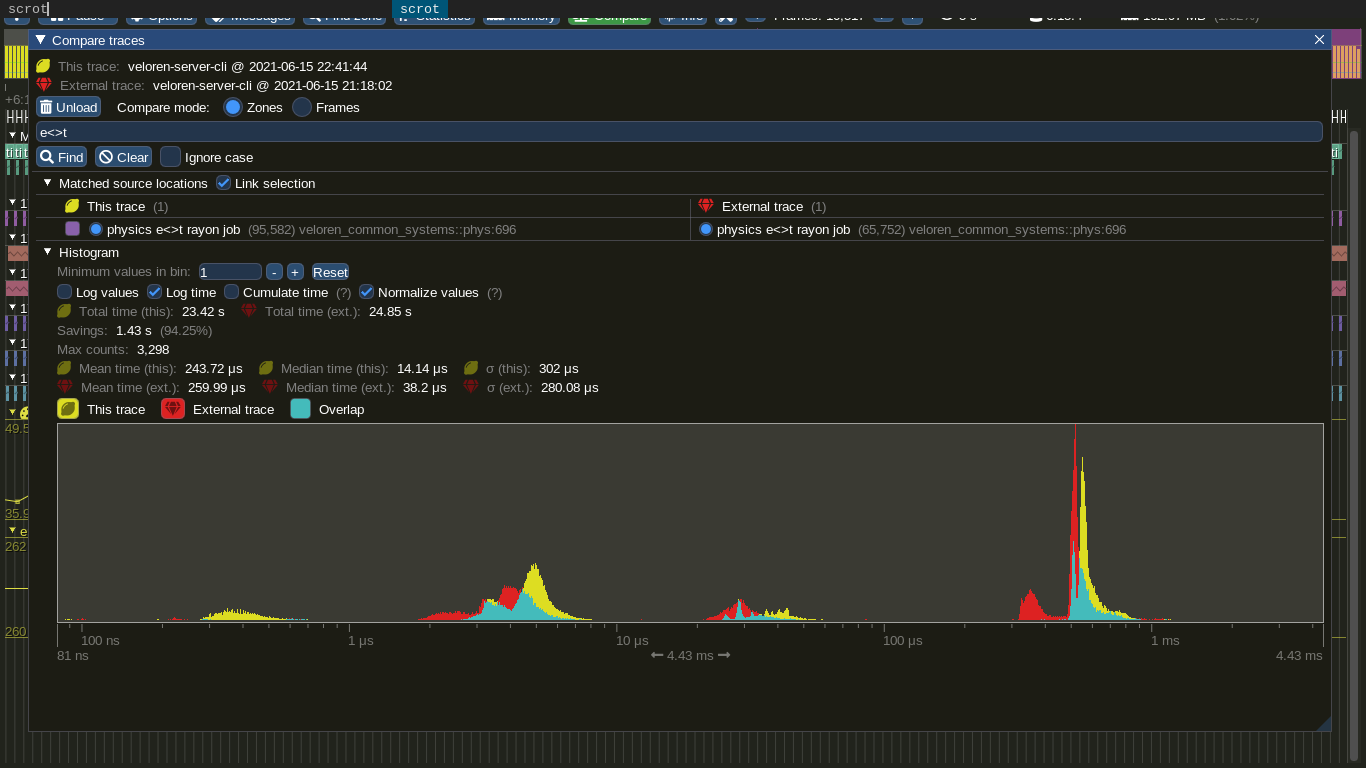
Econsim improvements @Christof
I finally found the mistake in the faster economy simulation code and the code got merged - server startup should be faster by several seconds.
After that, I started an RFC about short and long-term goals. Econsim will soon get more wares and professions to match the increased number of items, and the much more powerful crafting recipes. Also, prices will probably get independent of loot probabilities and become more raw material derived.
All about wgpu
A section by @imbris and @Sharp, edited by @Capucho and @AngelOnFira.
We now use the wgpu crate for our graphics!
After a long journey of refactoring our rendering code for wgpu, rebasing, refactoring new graphics features to use wgpu, updating the code across wgpu versions, testing on a plethora of platforms, fixing miscellaneous bugs, and rewriting parts of our CI cache generation with efforts from @Imbris, @Capucho, @Sharp, and others we have finally merged the long awaited 129 commit branch that switches our rendering code to this new graphics crate!
wgpu is the spiritual successor to the gfx (pre low level) crate we were using for graphics so it sits at a similar level of abstraction. However, wgpu provides a cleaner modern API that gives use more control and the ability to leverage the power of modern backends including vulkan, metal, and dx12. With gfx we only used the OpenGL backend and now with wgpu we have automatic support for multiple backends including automatic runtime backend selection.
The currently functioning backends are vulkan, dx12, metal, and dx11 (support for OpenGL is lost for the moment). We saw improvements in performance especially for Windows users with decent graphics cards that previously experienced a significant discrepancy in performance from Linux users with similar cards.
Now that this period of refactoring has been finished, we're excited to see the optimizations and features we can develop on this fresh graphics API.
Much thanks to @kvark and @cwfitzgerald ❤️ for answering the questions we had about wgpu, resolving bugs we encountered, and being extremely receptive to issue reports and pull requests!
Thanks to all the testers who helped us track down platform-specific bugs and make sure everything was mostly working everywhere!
Notable previous mentions of the wgpu refactor are in devblog-64 and devblog-100
Presentation modes option
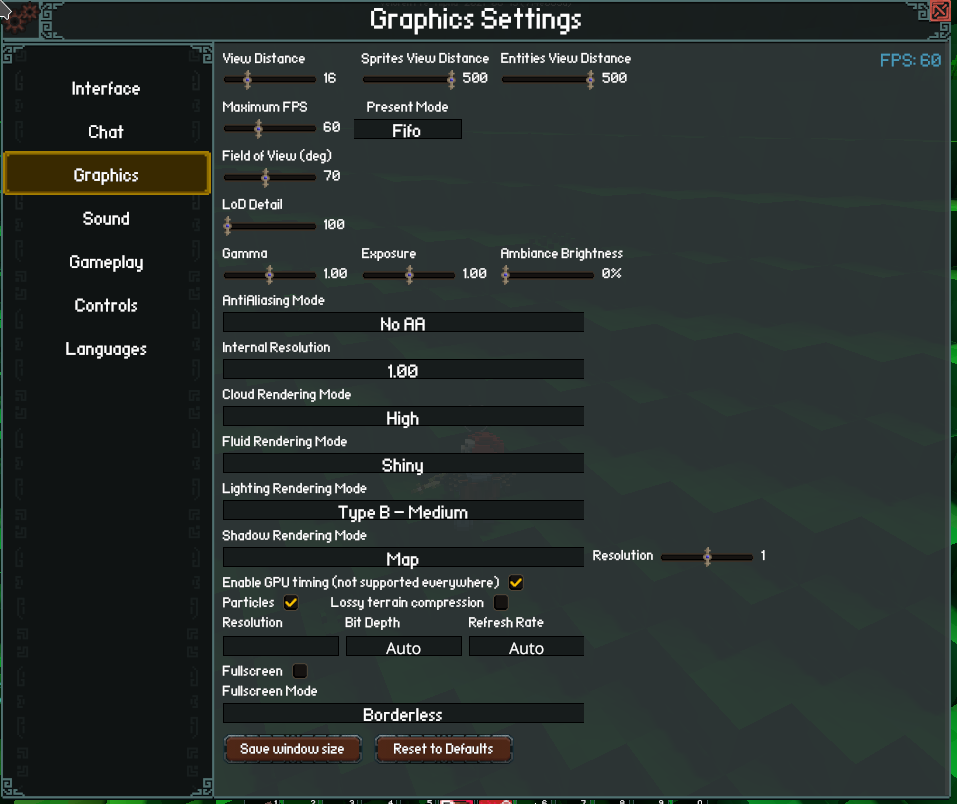
We added a new option in the graphics menu with the three presentation modes exposed by wgpu: Immediate, Mailbox, and Fifo. Selecting Fifo or Mailbox can be used to avoid screen tearing. Fifo corresponds to VSync and as such caps the frame rate at the display refresh rate. Immediate and Mailbox both fallback to Fifo within wgpu if that option isn't available on the current platform.
GPU timing with wgpu-profiler
While working on this refactor I discovered, via lurking on the Rust gamedev Discord and the wgpu matrix channels, that wpgu provided an API for collecting timestamps between sections of work on the GPU. This piqued my interest as I've previously had much success identifying and optimizing our CPU bottlenecks with the use of flame graph and Tracy while our GPU side performance was mostly opaque to me.
Thus, I started working on writing an abstraction to make it easier to instrument our rendering code with timestamps. While I was in the process of this, Wumpf released wgpu-profiler. I discovered it had everything I needed and nicely solved the complications of identifying timestamps which I was too focused on over-optimizing. It even included the ability to write out to a chrome trace which was pretty neat!
So I switched to wgpu-profiler, made a PR adding drop based scope wrappers around wgpu types, and deleted all the extra code I had for this in the Veloren codebase which was pretty satisfying. I then added scopes around all the major portions of our rendering (essentially one for each render pass and one for each pipeline).
To make it easy to access this new information I added a new option in the graphics menu to enable GPU timing. The timing values can be viewed in the HUD debug info (F3) and will be saved as chrome trace files in the working directory when taking a screenshot. It's mostly just supported on the Vulkan backend at the moment so if you don't see anything new in the debug info then the feature isn't available on your current backend/platform combination. I intend to eventually make the checkbox gray out in this case instead of having no indication. It would be neat to plot these values over time in the future. Chrome trace GPU timing in HUD debug info
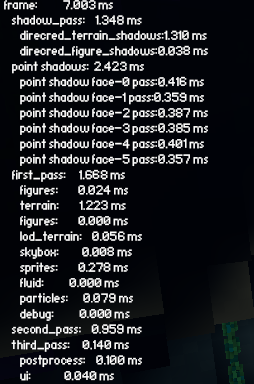
We can also now use tooling for profiling vulkan and dx12 such as this profiler from AMD: https://gpuopen.com/rgp/ Example RGP profile on Ryzen 3 3200U integrated graphics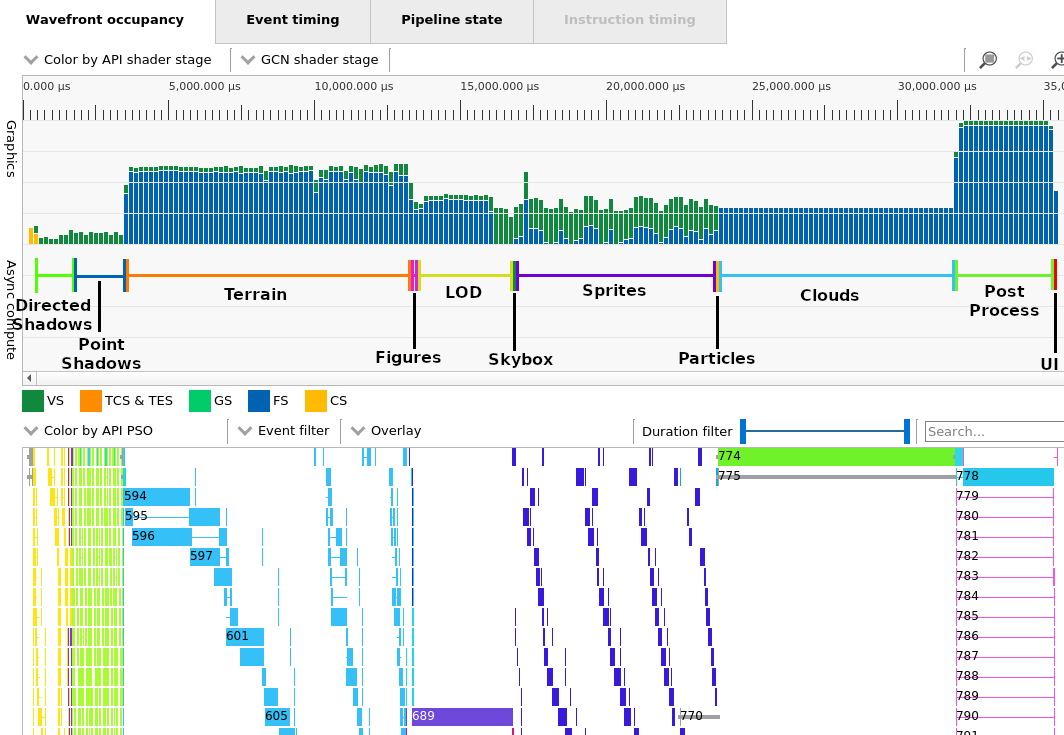
Sprite optimization
High sprite view distances previously had a really large impact on the CPU. We used instancing for sprites to draw multiple ones with the same model within a single draw call. However, within a chunk there several different sprite kinds (some with multiple variations in their models) leading to a large number of draw calls and significant CPU overhead when trying to draw more sprites farther away.
To reduce the number of draw calls we need to make I combined all the sprite models into a single buffer of vertices and then used a technique called vertex pulling to fetch the vertex data from this buffer within the vertex shader by determining the location in the buffer from the index of the current vertex combined with the mesh offset for the current instance.
This moved the bottleneck for sprites into the vertex shader both because this introduced a bit more work in the shader and because sprites simply have a lot of vertices and were no longer limited by the CPU. To help alleviate this I converted all our quad drawing (i.e. what all our terrain, figures, and sprites are made of) to use an index buffer to reduce the number of vertices that need to be processed per quad from 6 to 4 (as the GPU should cache vertices with the same index).
This helped and also led to small gains for shadow rendering times, presumably terrain and figures also benefited but the cost of the fragment shader for those is far greater in typical scenes. I think we can squeeze more performance out of sprites by optimizing the vertex shader further and reducing the amount of per-instance data. Another area where we can tackle this is reducing the vertices used for sprites that are far off and take up only a few pixels. We already have different LOD levels that reduce the number of vertices but we may be able to go further and simply render 2D billboard-style sprites for these.
Reversing the depth buffer
One of the bigger wins from switching to wgpu is that it lets us abandon the OpenGL depth buffer. To make a long story short, the standard method for calculating depth buffers is the worst possible way to do it. They should be computed "backwards" from how people normally set them up due to this taking far better advantage of the way floating point precision works (in fact, it is nearly optimal for floating point)!
Unfortunately, since it takes some fairly involved math to realize this, the OpenGL spec was published in a way that makes it impossible to realize the benefits of reversed depth buffers, due to setting depth planes to go from -1 to 1 instead of 0 to 1; the conversion to 0 to 1 must then be done in the drivers by computing depth * 0.5 + 0.5, which is pretty much the worst possible thing you can do for floating point accuracy and negates the reversal effect. wgpu follows the far more sensible Vulkan, Metal, and DirectX option, and sets depth buffers from 0 to 1, enabling us to realize the effect.
The practical upshot of this is that we can set the near plane much, much closer than before, while extending the far plane to (effectively) infinity, while retaining better precision than before at literally every point in the whole range (except maybe within a very tiny fraction of a block in front of the near plane). This should help us improve clipping since it solves the most annoying aspect of it (near plane) and also lets us render much bigger maps without noticeable artifacts (unless you zoom all the way out).
Organizing bind group and pipeline switching
To avoid redundant state changes (setting pipelines, bind groups, vertex buffers) as much as possible. We created a series of "Drawer" types that wrap a reference to the render pass and guarantee for instance that a certain pipeline is in use. We have a top level Drawer that exists transiently during the recording of the frame:
pub struct Drawer<'frame> {
encoder: Option<ManualOwningScope<'frame, wgpu::CommandEncoder>>,
borrow: RendererBorrow<'frame>,
swap_tex: wgpu::SwapChainTexture,
globals: &'frame GlobalsBindGroup,
// Texture and other info for taking a screenshot
// Writes to this instead in the third pass if it is present
taking_screenshot: Option<super::screenshot::TakeScreenshot>,
}
This hold references to bits of the render state that we need and owns the command encoder. Then for example, there is a method to start the first render pass that returns a FirstPassDrawer:
/// Returns None if all the pipelines are not available
pub fn first_pass(&mut self) -> Option<FirstPassDrawer> {
let pipelines = self.borrow.pipelines.all()?;
// Note: this becomes Some once pipeline creation is complete even if shadows
// are not enabled
let shadow = self.borrow.shadow?;
let encoder = self.encoder.as_mut().unwrap();
let device = self.borrow.device;
let mut render_pass = encoder.scoped_render_pass("first_pass", /* snip */ });
render_pass.set_bind_group(0, &self.globals.bind_group, &[]);
render_pass.set_bind_group(1, &shadow.bind.bind_group, &[]);
Some(FirstPassDrawer {
render_pass,
borrow: &self.borrow,
pipelines,
globals: self.globals,
shadows: &shadow.bind,
})
}
But before returning it two bind groups are set:
render_pass.set_bind_group(0, &self.globals.bind_group, &[]);
render_pass.set_bind_group(1, &shadow.bind.bind_group, &[]);
In subsequent drawing, we can then rely on these bind groups being set (as long as we maintain that they aren't overridden which we accomplish by keeping all the logic which sets bind groups (and other things) in this one module). Then e.g. to start drawing terrain we create a TerrainDrawer setting the pipeline and the index buffer in the process:
pub fn draw_terrain(&mut self) -> TerrainDrawer<'_, 'pass> {
let mut render_pass = self.render_pass.scope("terrain", self.borrow.device);
render_pass.set_pipeline(&self.pipelines.terrain.pipeline);
set_quad_index_buffer::<terrain::Vertex>(&mut render_pass, &self.borrow);
TerrainDrawer {
render_pass,
col_lights: None,
}
}
Such that when we draw all the chunks we only need to set the additional bind groups and vertex buffer specific to each chunk:
impl<'pass_ref, 'pass: 'pass_ref> TerrainDrawer<'pass_ref, 'pass> {
pub fn draw<'data: 'pass>(
&mut self,
model: &'data Model<terrain::Vertex>,
col_lights: &'data Arc<ColLights<terrain::Locals>>,
locals: &'data terrain::BoundLocals,
) {
if self.col_lights
// Check if we are still using the same atlas texture as the previous drawn chunk
.filter(|current_col_lights| Arc::ptr_eq(current_col_lights, col_lights))
.is_none()
{
self.render_pass
.set_bind_group(2, &col_lights.bind_group, &[]);
self.col_lights = Some(col_lights);
};
self.render_pass.set_bind_group(3, &locals.bind_group, &[]);
self.render_pass.set_vertex_buffer(0, model.buf().slice(..));
self.render_pass
.draw_indexed(0..model.len() as u32 / 4 * 6, 0, 0..1);
}
}
Future of OpenGL support
With this transition, we gain access to a lot of new graphics backends, but we now no longer have OpenGL support. This mainly affects Linux users as support for older Windows machines is provided through dx11. Nevertheless, we may regain some form of OpenGL support on Linux in the future. The backend abstraction layer for wgpu was recently rewritten and moved into the main wgpu repo removing a lot of the barriers to getting an OpenGL backend working.
Shaderc adventures
To use our GLSL shaders with wgpu we have to compile them to SPIRV. Currently, the only viable option for this is using shaderc. However, shaderc is a C++ dependency and thus has the potential to bring complications to the build process which it does. Building shaderc requires git, cmake, and python to be installed and also ninja on Windows. This adds extra steps for new contributors looking to compile Veloren.
Additionally, shaderc introduced complications into our cross compiled CI builds (for non Linux platforms). Cross compiling to Windows, I ran into this issue which I was only able to solve by using the POSIX threads version of MinGW which necessitated distributing some DLL files.
Cross compiling to macOS also had various issues with compiling and/or linking shaderc. After several attempts including trying to use prebuilt versions of shaderc, we eventually switched to natively building on a macOS runner which was admittedly a somewhat useful change outside of getting shaderc working as we have had other issues with cross compiling to macOS. Shaderc is also pretty massive and appears to add at least ~10 MB to our binary size. Hence, we are really looking forward to when naga, a shader translator library written in pure Rust, will be able to replace shaderc for our purposes.
CPU profiling
Since we had a major refactor I thought it would be neat to examine the CPU profiles of the work being done during rendering. Most of the CPU side time for rendering appears to be spent in Tracy profile showing ~2 ms to queue rendering of everything for a frame Flamegraph snippet showing where `run_render_pass` spends time Settings used for CPU profilingrun_render_pass:

Future directions
Our future with wgpu is bright. Because its API is much closer to that of modern graphics drivers, it should be much easier to incorporate newer hardware features (at least if they have a little bit of cross-platform support). We also have a great opportunity to help influence the shape of not only wgpu, but the WebGPU specification itself, to make it better for games in general.
Finally, having made this switch lets us focus on other rendering improvements we'd been putting off in order not to block wgpu work (or which were blocked by lack of wgpu), such as:
- Separate the voxygen renderer module into its own crate (e.g. we can use it in a voxel editor)
- Create a small renderer engine test/demo for rapid iteration and testing.
- Rendering on multiple threads (impossible before wgpu, currently waiting on removal of locks in wgpu).
- Deferred rendering (making large numbers of unshaded point lights cheap).
- Move completely to
nagaonce it has GLSL support and can handle our shaders. - SMAA
- Improved LOD rendering (including things like trees, sites, and maybe even some form of sprites).
- Smarter and more accurate shadows with occlusion queries (useful for many other purposes as well) and Z-partitioning.
- Faster and smarter chunk updates, both for initial rendering and updates to things like sprites, to reduce apparent load times.
- More physically correct HDR, allowing us to remove various lighting hacks (should especially help at night).
- Take advantage of compute shaders and GPU-side buffer updates to speed up CPU-limited operations.
- (Maybe) explicit tiled rendering, tessellation shaders, and multiple queues, if/when supported!
- And much, much more!

Out for an early morning dip. See you next week!
