This Week In Veloren 27
Thanks to all of the contributors this week, @Zesterer, @Timo, @Xacrimon, @xMAC94x, @Pfau, @Qutrin, @Vercidium, @telastrus, @Songtronix, @imbris, @YuriMomo, and @Slipped!
Programming
0.3 Release
This week, 0.3 was released! This version was a long time coming, and there has been a ton added to Veloren. Here is a small list of the major changes in this version:
+ XP and leveling
+ Better combat, movement, and animations
+ Enemies, bosses
+ Better world generation, more biomes
+ Build mode
+ Caves, lanterns, lights, dungeons
+ Character customization, multiple races
+ Inventories (WIP)
+ Day/night, better shaders, voxel shadows
+ Many performance optimizations
You can download 0.3 on the main website here. We are excited to start work on 0.4. We will be having a meeting in the next week or so to discuss what our goals are for the next release.
Here is a list of all of the contributors that made 0.3 possible:
@Zesterer
@Timo
@Pfau
@Qutrin
@Songtronix
@Xacrimon
@Slipped
@edocyeknom
@Cody
@scorpion9979
@Desttinghim
@sheldon_knuth
@imbris
@liids
@LunarEclipse
@AngelOnFira
@xMAC94x
@Cedric
@Vechro
@Nero
@jrvf
@Tesseract
@Geno
@Thomas_Jullien
@Jessie_Mancer
@YuriMomo
Graphics Analysis by @Vercidium
This week, @Vercidium stopped by our Discord Server. He is a developer currently working on a voxel game called Sector's Edge. With his knowledge of graphics debugging he was able to provide insight into how Veloren is performing. @YuriMomo, our resident graphic analyst had some good discussions with him on this topic.
Using NVIDIA’s Nsight tool, he analyzed how different parts of the rendering pipeline performed at different view distances. These parts include:
- How fast the fragment and vertex shaders are running
- How often the shaders and GPU are idle
- Memory reading and writing
Shader performance is determined by the code they are running and the memory they read from and write to. In our case, the terrain shader was rendering 722676 triangles every frame and for 46% of the time, it was reading primitive data (triangles) from memory. This either means that either the shader code is highly optimized and finishing before more triangle data is loaded, or too much data is being processed. To determine which is the limiting factor, @Vercidium analyzed a few more metrics provided to us by NSight.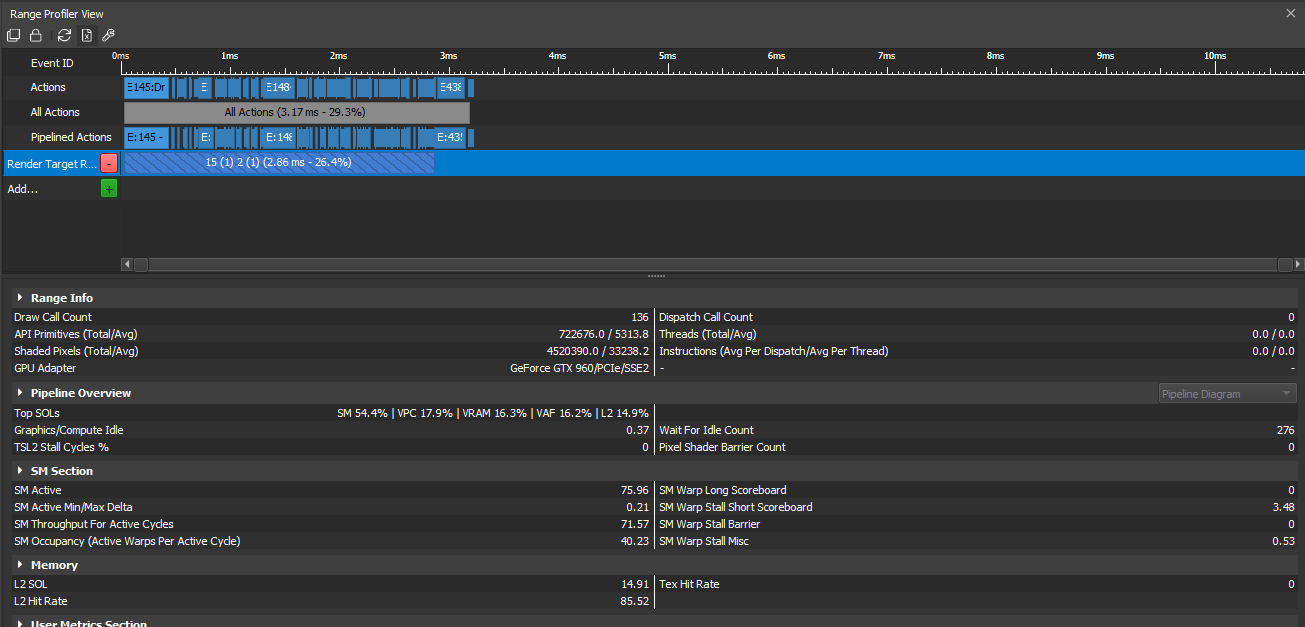
The ‘Top SOLs’ metric is the first section we will look at as it displays the top 5 parts of the rendering pipeline that are limiting the performance. Our top limiting metrics are:
- Stream Multiprocessors (SM) are physical processors on the GPU that run the fragment and vertex shaders
- Viewport Culling (VPC) ensures that pixels outside the screen aren’t processed
- Video RAM refers to data that is read/written from the GPU’s memory
- Vertex Attribute Fetch is responsible for loading primitive data into the vertex shader for processing
- A Level-2 (L2) cache is attached to each VRAM partition and allows commonly accessed data to be retrieved quicker
Since VRAM is the 2nd highest SOL, the GPU’s memory bus used for accessing primitive data from memory is full and subsequent shaders are delayed until these queues have been processed. This is caused by either a high triangle count or the amount of data stored in each triangle.
When all top SOLs are less than 60%, NVIDIA states that the pipeline is under-utilized. Based on the SM Active % percentage (just below the SOL metric), the GPU shaders are completely idle for 24% of the time. Vercidium determined that this could be caused by a few different things.
First of all, extra non-rendering GPU commands being run between each draw call. This can be optimized on the CPU.
Second, chunks of blocks are being rendered that are not visible on the screen. Since Viewport Culling is the 2nd highest SOL, this means that the GPU is doing a lot of work determining whether triangles are on the screen. By culling these chunks on the CPU, the GPU will be able to spend more time processing the triangles that will end up visible to the player A nice little camp setup
Finally, since VRAM and VAF are the 3rd and 4th highest SOL, this means that the GPU is doing more work reading primitive data into the vertex shader than writing pixels out from the fragment shader (CROP - color read/write operation is another metric, which isn’t in the top 5 SOLs). This means that there is excessive primitive data loaded from VRAM every single frame.
This can be reduced by combining similar block faces and using a 32x32x32 RGB colour texture to determine the colour of each block, or implementing a Level-of-Detail system to simplify chunks that are further away from the camera. This will reduce both the size of each vertex and the number of vertices loaded each frame. Using a texture to determine block colour is recommended as the TEX SOL (texture access) is currently running at 0% throughput, so there is room for textures to be used without slowing the pipeline down.
When running at a higher view distance, the number of chunks rendered increases from 136 to 766. Here, viewport culling has become the highest SOL and by diving deeper into the numbers, Vercidium determined that 1/3rd of all chunks rendered end up outside the screen. With a total triangle count of 4.6 million per frame, 1.5 million triangles aren’t visible.
The second metric that increased is the Graphics/Compute Idle percentage, which means that for 25% of the time, the entire GPU is idle and can be seen by the two large gaps in the ‘Pipelined Actions’ row below: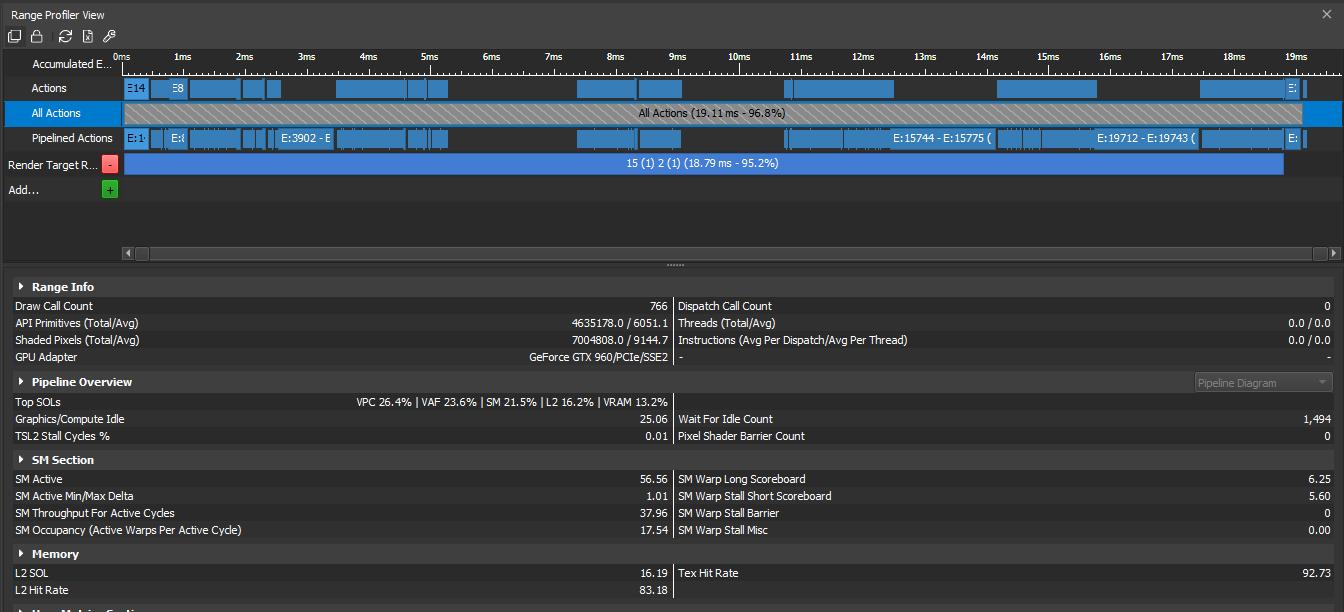
This is caused by a delay on the CPU, where no instructions are being sent to the GPU. The reason for this is yet to be determined, but once solved will increase FPS for all players by 25%.
The ‘Wait For Idle Count’ metric increased from 276 to 1494, meaning that the GPU is waiting for non-drawing commands to finish before it is able to run the shaders again. After filtering through the commands received by the GPU, Vercidium found that the framebuffer is being bound between each draw call, i.e. ‘Draw, Bind, Draw, Bind, etc.’, rather than ‘Bind, Draw, Draw, Draw’. This is caused by a problem in GFX, which is the Rust library that Veloren uses to render the chunks.
Vercidium also provided some quick changes that can be done to increase performance slightly, such as:
- Rendering to an SRGB8 framebuffer rather than an RGBA_16F format. This means that 32 bits will be stored per pixel - rather than 64 - and the memory output from the fragment shader will be reduced by half.
- Stencil testing was enabled through the entire render process, but nothing was written to the stencil buffer. By changing the depth attachment from GL_DEPTH24_STENCIL8 to GL_DEPTH24, depth writing and comparison will be quicker as no bitwise operations will be required when reading from the depth buffer.
Color work by @imbris
This week I worked on making the colors of the voxel models more accurate by accounting for the differences between SRGB and linear RGB (see the imbris/SRGB branch). SRGB is widely used in color pickers and for the colors we normally specify using integer values of 0 to 255.
These colors are intuitive to work with despite being non-linear, meaning that a value of 200 is more than twice as bright as 100. This is because our eyes perceive light in a similar non-linear fashion. A light that emits twice the number of photons doesn't look twice as bright to our eyes. Furthermore, because it more closely matches the human eye, when limited to 8 bits per component the available shades are visually more evenly distributed when using SRGB. The top is linear RGB, the bottom uses SRGB
Hence, using an SRGB based color representation allows us to pass a wider variety of colors to the shaders will using 8 bits per component (i.e. 24-bit color). The 24-bit colors from loaded voxel models or generated terrain, some of which are based on voxel models, are passed to the shaders where previously they were treated as already being in a linear color space (shaders assume this).
Thus, when drawing to the screen the colors were inaccurate and appeared washed out. This was adjusted for by adding a postprocessing shader which adjusts the color by converting it into HSV, increasing the saturation, and then converting back out of HSV. While this looks nice, it doesn't represent the original colors very well. This can make it difficult to predict what the colors of a model will look like in the game as a figure or part of the terrain.
Additionally, any other client front-end would have to follow this same transformation to obtain similar colors as voxygen. I set out to handle the SRGB values by adding a function to the shaders which transform them into a linear representation and then applying this to the terrain colors, the figure colors, and the light (the placeable lights) colors. Before @imbris' changes After the changes

I also removed the post-process color correction. This left the colors of the terrain looking wildly different because they were selected with the old set of transformations present. I am currently at the point of fixing these colors. However, this is not straightforward because the hue transformation was applied after everything else, including lighting. I can't simply apply it to these original values and then, treating them as linear values like they were before, transform them into the SRGB space before converting them to 24-bits.
This issue is compounded by the fact that the world-gen calculates the colors of individual blocks via linear interpolation of the base colors. This is similar to the lighting the saturation shift before and after this interpolation won't be equivalent. Furthermore, to test tweaks to these colors requires re-compilation. Another set of colors which will need tweaking is the sky, fog, and ambient lighting for which thankfully adjustments can be seen immediately due to hot-loading of the shaders.
Going into working on making SRGB handling more accurate I knew I would be working on the shaders. So, first I decided to add loading the shaders at runtime instead of compiling them into the executable (a feature we have been planning to add for a while but which no one had gotten around to doing). This was before I converted the terrain colors to SRGB. The tweaks in the previous images are just trying to correct for the removal of saturation in the postprocessing after switching the terrain colors into SRGB. Whereas this was just after changing the shaders.
While this was fairly simple using the existing asset system, I ended up going one step further to add hot-loading of the shaders. That is, detecting when the shader files are edited, reloading from the disk, and re-compiling. This is accomplished via the notify crate which can be used to detect changes to watched files.
I added yet another loading function load_watched which calls the regular load function but also takes a &mut ReloadIndicator and adds the given specifier to be watched for changes. A ReloadIndicator is basically an Arc<AtomicBool> which gets flipped on whenever an asset is reloaded and flipped off whenever it is checked.
Once the asset is reloaded, a call to a load function will return a fresh Arc<MyAsset>. All of the watching of and reloading of assets is done in a background thread which flips the AtomicBools after the reloading is complete.
Other Work
@Qutrin has been working on adding some more content to the progression system. Now, as you level up, you'll gain more health. @Timo also added a bit to the progression system, with making XP gain dependant on the level of the enemy killed.
A new Request For Comments (RFC) system has been created. RFCs allow ideas that are more complex to have discussion specifically around them. This is particularly useful for design ideas. Some new sections in the Some voxel work by @DemonicGame Design section of the Discord server make use of RFCs. Take a look at the RFC repo here.
@Timo worked on some network performance improvements to physics updates. When nothing changes, updates are no longer sent to the client. @Xacrimon has been working for a while now on memory improvements and has made strides implementing a data structure for storing entities more densely in memory. More to come on this in the upcoming weeks. @Geno implemented a FOV slider that has been merged into master. Be sure to check this setting out, it can help your camera in the game.
