This Week In Veloren 34
Thanks to this week's contributors, @Xacrimon, @imbris, @Pfaunenauge, and @Zesterer!
Contributor work
Many contributors are still getting into the swing of school. But we still have some great progress this week! @Yeedo has continued work on the gliding system. @imbris, @Zesterer, and @Xacrimon put in some great optimization work. @Pfau worked on fixing bugs within the character creation screen. Visuals added for deleting characters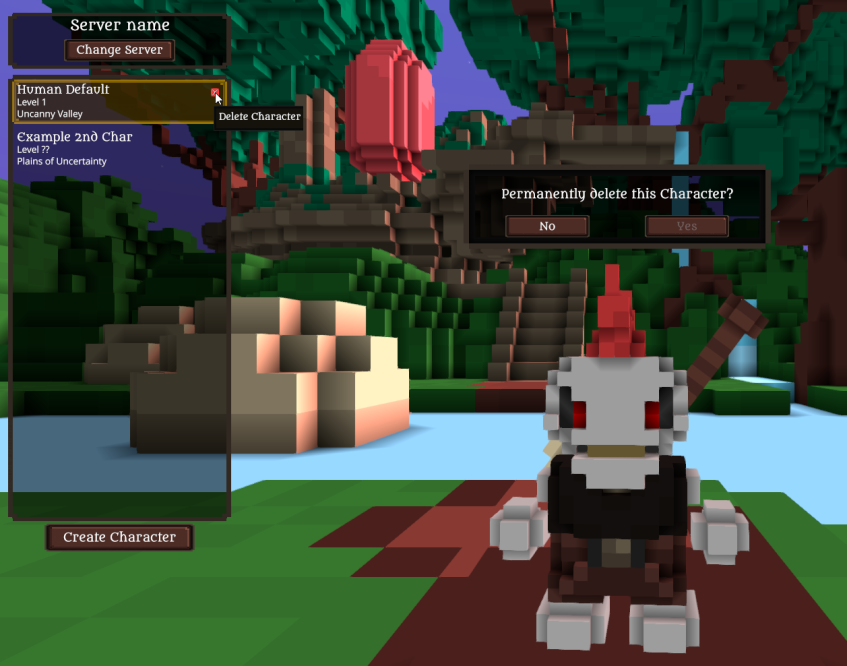
Improvement to Worldgen with @imbris
@imbris has spent lots of time this week working on worldgen improvements. Before the work started, a flame graph was recorded. Flame graphs are used to show where the most time is being spent within different functions. You can see the initial flame graph here: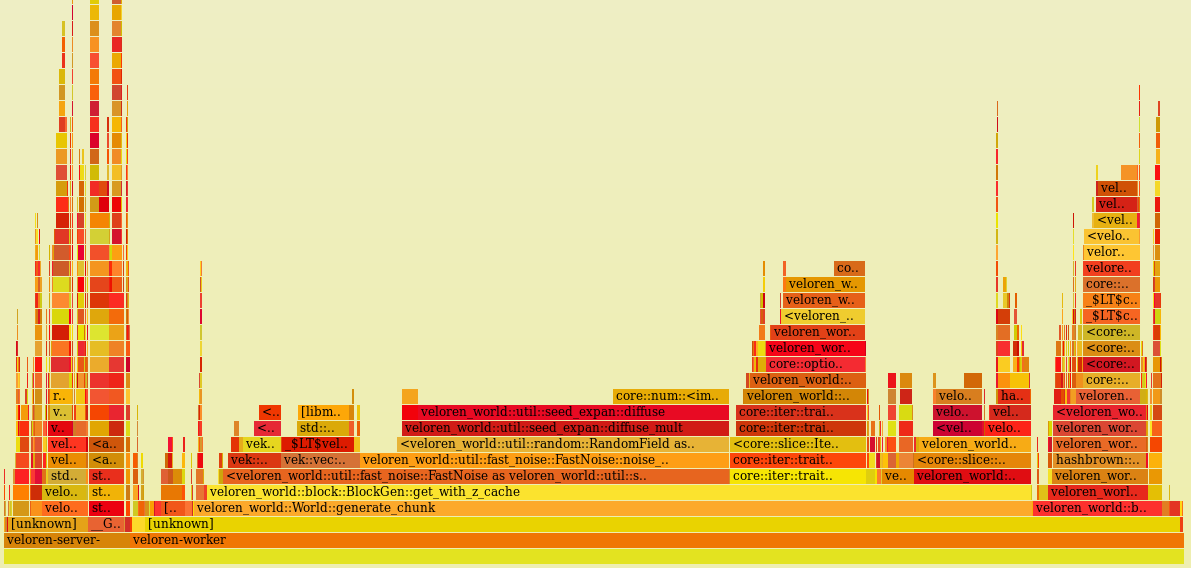
The goal is to look at the widest items and try to make them thinner. @imbris noticed that a lot of time was being spent in the seed_expan::diffuse function. This one is near the middle of the flame graph image. You can see that each function below it has to be just as large as it is waiting on the diffuse function to move along. This function used some code magic:
/// Simple non-cryptographic diffusion function.
pub fn diffuse(mut x: u32) -> u32 {
x = x.wrapping_add(0x7ed55d16).wrapping_add(x << 12);
x = (x ^ 0xc761c23c) ^ (x >> 19);
x = x.wrapping_add(0x165667b1).wrapping_add(x << 5);
x = x.wrapping_add(0xd3a2646c) ^ (x << 9);
x = x.wrapping_add(0xfd7046c5).wrapping_add(x << 3);
x = (x ^ 0xb55a4f09) ^ (x >> 16);
x = x.wrapping_add((1 << 31) - 13) ^ (x << 13);
x
}
@Xacrimon was able to simplify this function by combining a few of the operations. It gives mostly the same effect, but much more quickly:
/// Simple non-cryptographic diffusion function.
#[inline(always)]
pub fn diffuse(mut a: u32) -> u32 {
a ^= a.rotate_right(23);
a.wrapping_mul(2654435761)
}
And with that, we are already able to see improvements in the flame graph! No longer do we have the long wait in the middle of the flame graph: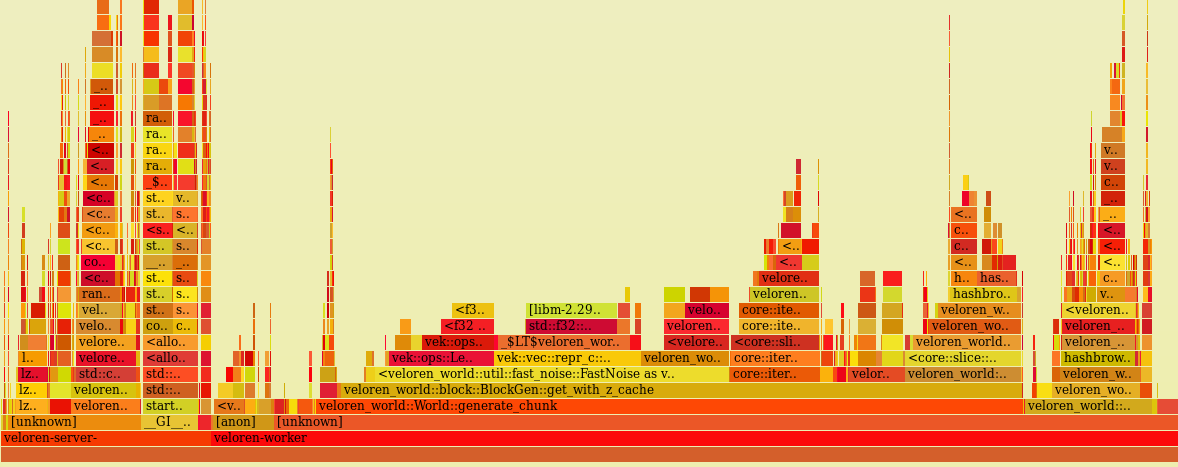
@imbris took a closer look at some other sections, specifically the Fastnoise function. While they had improved it during diffuse's improvements, it still took almost half of the time spent generating a chunk.
The middle section where it was calling into libm.so was a cosine used for cosine interpolation to smooth the noise.
let factor = pos.map(|e| 0.5 - (e.fract() as f32 * f32::consts::PI).cos() * 0.5);
This was being used instead of linear interpolation because it gave a much smoother transition (e.g. for colors). You can take a look at a nice visualization of cosine vs linear interpolation here. Thus, @imbris set out to find an interpolation method that was similar to cosine but cheaper. They stumbled upon Smoothstep which is almost indistinguishable from cosine.
let factor = pos.map(|e| {
let f = e.fract().add(1.0).fract() as f32;
f.powf(2.0) * (3.0 - 2.0 * f) // <- smooth step
});
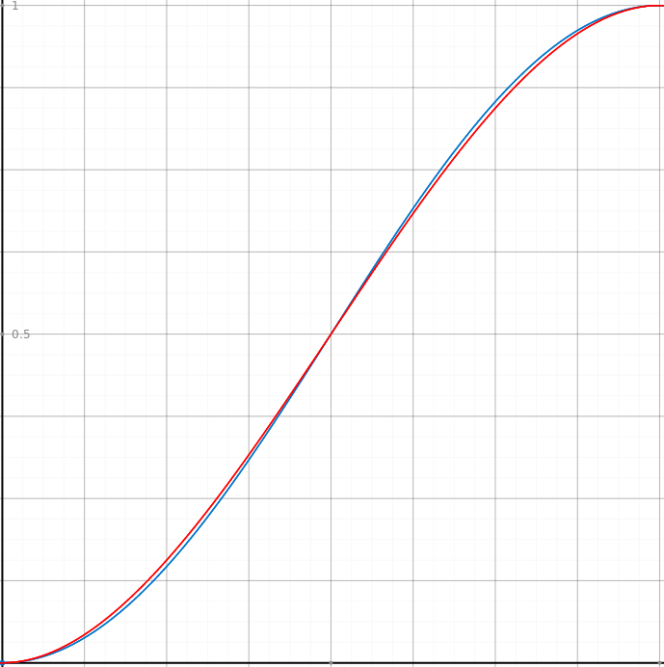
Blue is cosine, and red is Smoothstep
As you can see in the figure above, both are nearly identical. Additionally, @imbris noticed that 2/3 of the time spent lerping the noise with the factor calculated above was in clamping the factor when it is known that the factor will always be between 0.0 and 1.0. The clamp function in the flame graph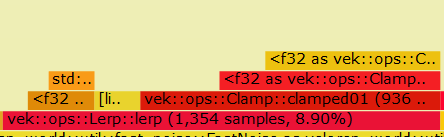
Thus, @imbris was able to avoid the clamping check and replaced the cosine interpolation with Smoothstep. We now had this flame graph: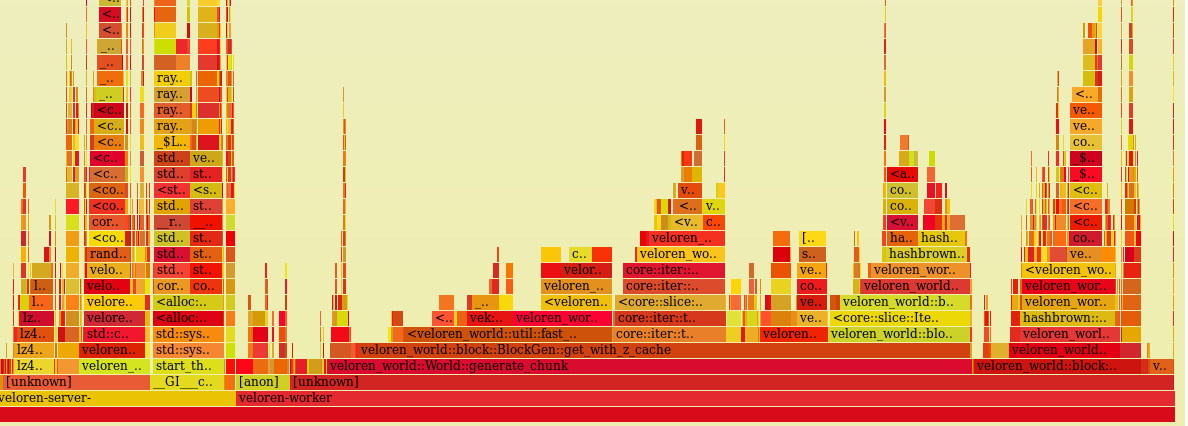
Looking good! A lot of fat has been trimmed in those greedy areas. At this point, @Zesterer pointed out that the cache in this section could be improved: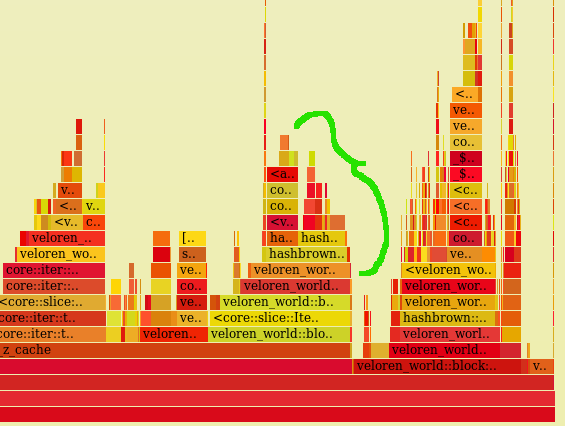
So @imbris, @Zesterer, and @Xacrimon collaborated to create a more efficient, fixed size, small cache that wasn't on the heap. It also used a less expensive custom hash function. @Zesterer also made the bounds-checked generation much more precise, which lead to a very significant reduction in worldgen time. Feel free to check out !504 and !507 to see the relevant MRs. The final flame graph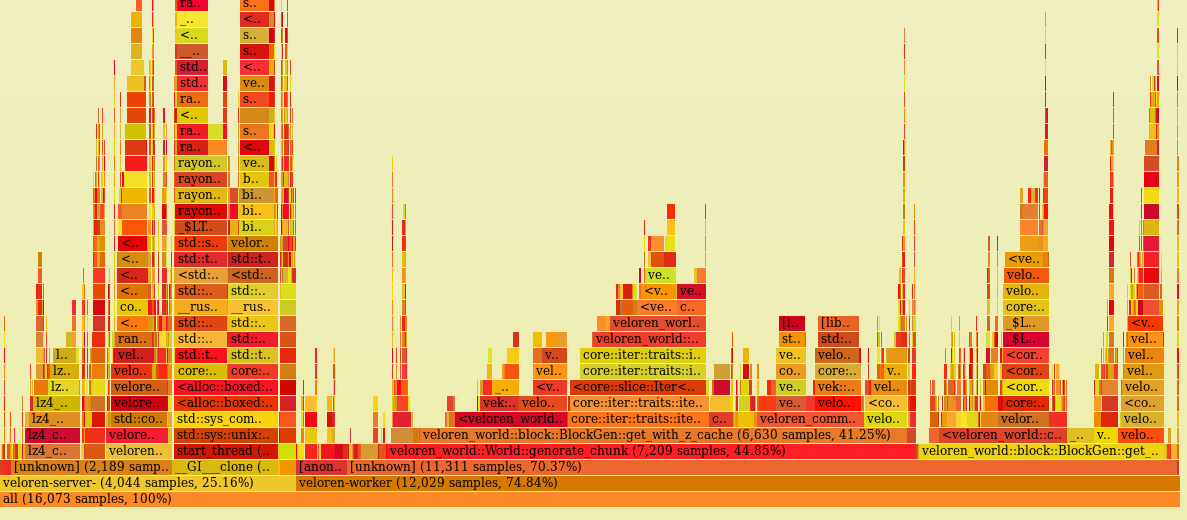
There is a lot more work to go in the optimization field, but it will always be an ongoing process. @Zesterer gave some insight into some future work.
So at the moment, we go through the whole process of generation for every block. That means that there's a hell of a lot of code being run each time we try to sample a block. I strongly suspect that this is very unfriendly for the instruction cache. So I would propose to move to a system where, in an almost ECS-like manner, we instead apply the generation process in layers with the whole chunk being operated upon every time. This might even allow the compiler to parallelize (via SIMD) a bunch of things too.

Exploring the frost lands. See you next week!
